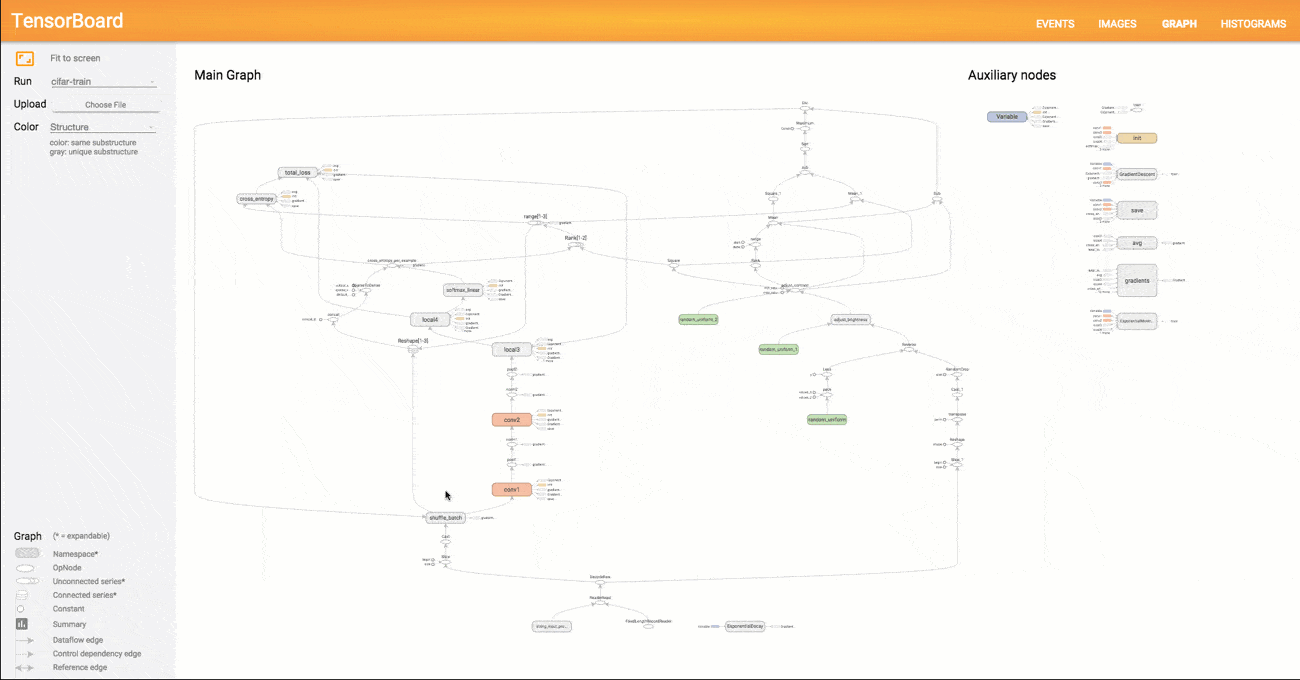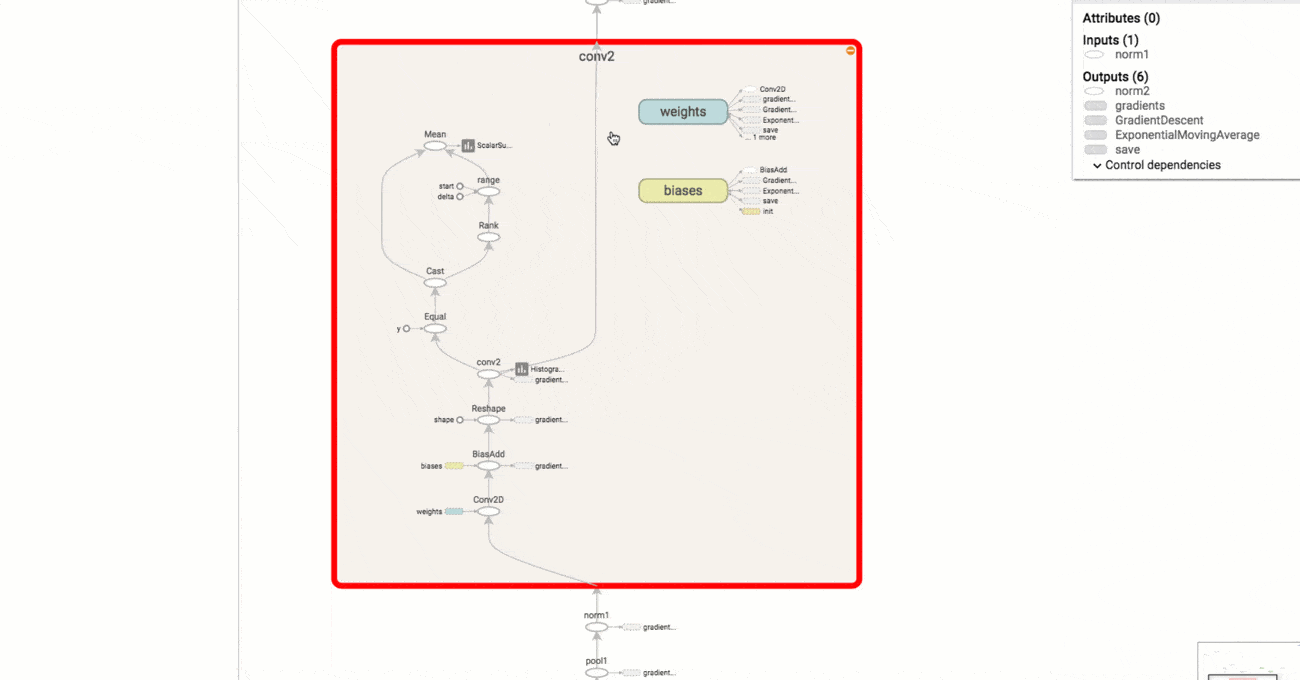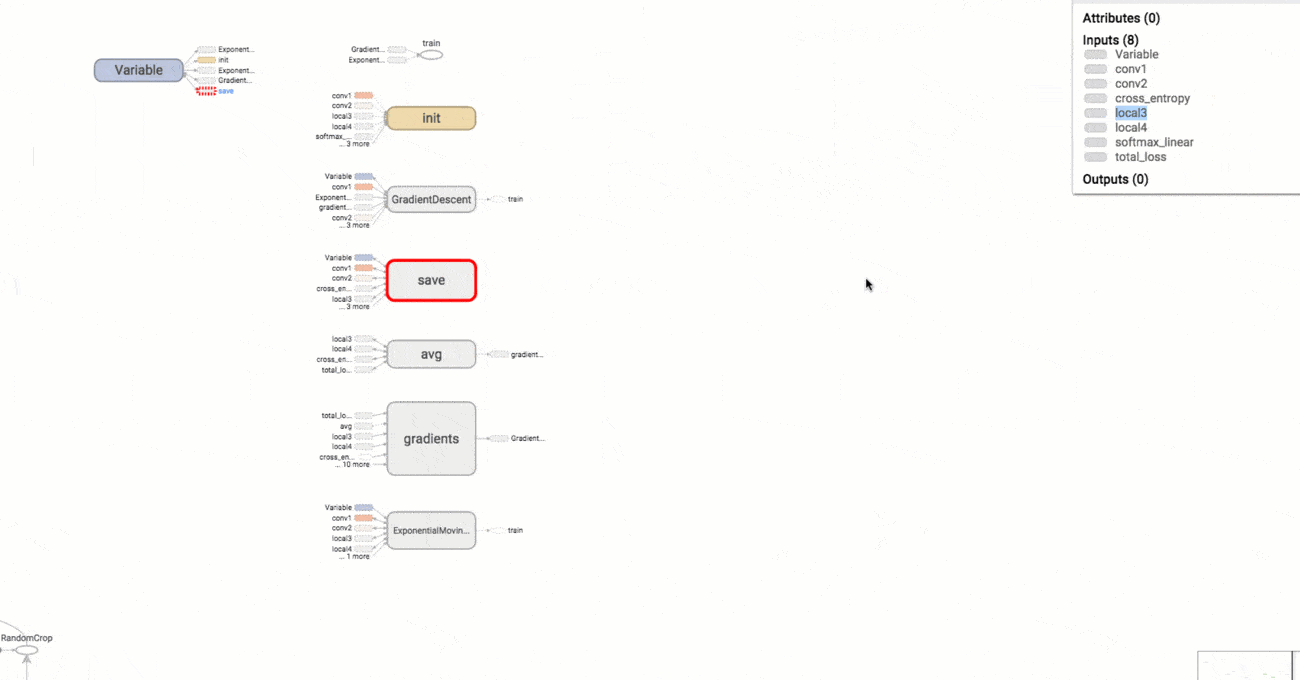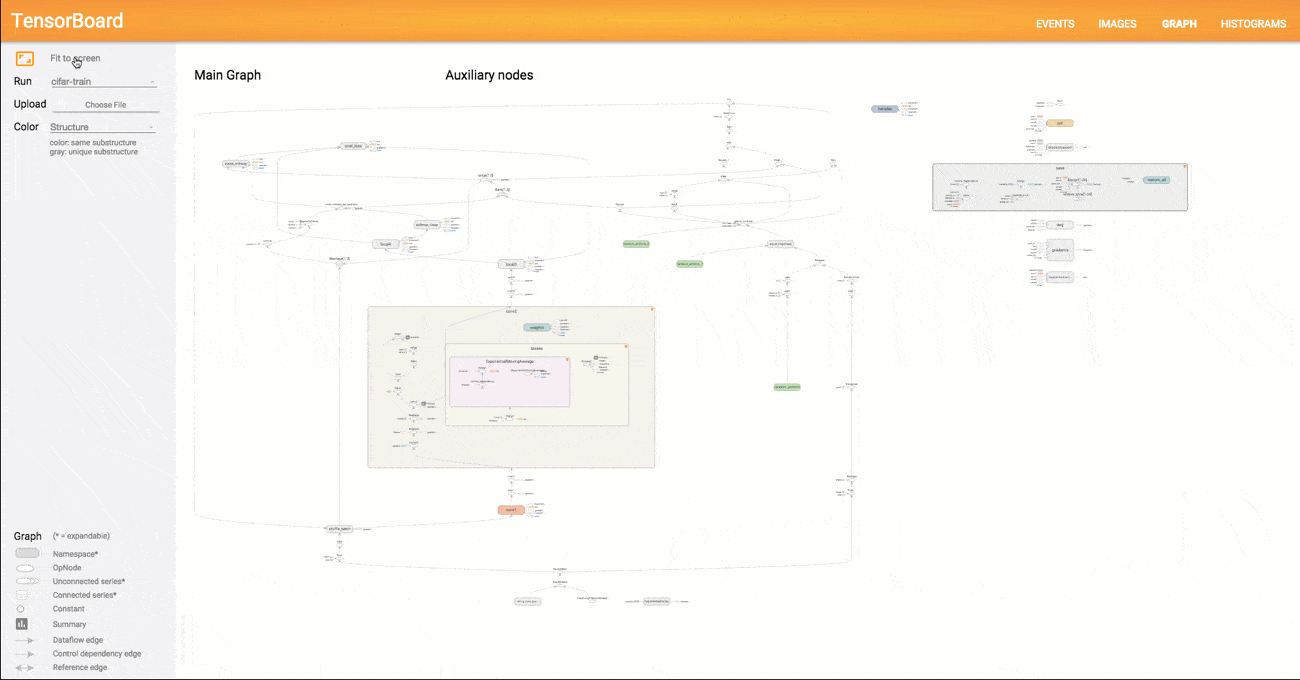
3# a rank 0 tensor; this is a scalar with shape [] [1., 2., 3.] # a rank 1 tensor; this is a vector with shape [3] [[1., 2., 3.], [4., 5., 6.]] # a rank 2 tensor; a matrix with shape [2, 3] [[[1., 2., 3.]], [[7., 8., 9.]]] # a rank 3 tensor with shape [2, 1, 3]
# Model parameters W = tf.Variable([.3], dtype=tf.float32) b = tf.Variable([-.3], dtype=tf.float32) # Model input and output x = tf.placeholder(tf.float32) linear_model = W * x + b y = tf.placeholder(tf.float32)
# loss loss = tf.reduce_sum(tf.square(linear_model - y)) # sum of the squares # optimizer optimizer = tf.train.GradientDescentOptimizer(0.01) train = optimizer.minimize(loss)
# training data x_train = [1, 2, 3, 4] y_train = [0, -1, -2, -3] # training loop init = tf.global_variables_initializer() sess = tf.Session() sess.run(init) # reset values to wrong for i inrange(1000): sess.run(train, {x: x_train, y: y_train})