include custom labels of k8s objects
最近有接触到一些带 GPU 的机器作为 K8S 的工作节点,因为使用了 GPU Operator 去管理驱动,所以需要为 kube-state-metrics 添加一些自定义的标签收集设置,才能比较方便的在 Prometheus 查询以及在 Grafana 中展示。
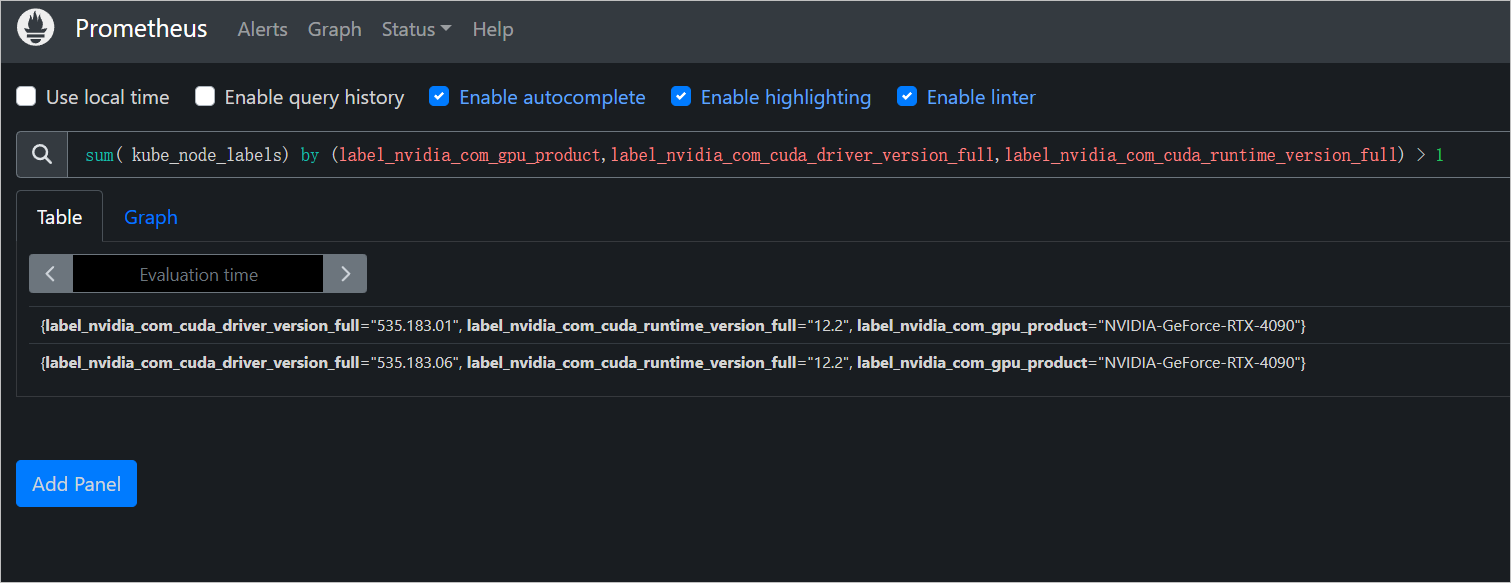
设置的方式比较简单,通过给 kube-state-metrics 添加额外启动参数就可以收集了。
因为我这里是使用的 Kube Prometheus Stack 的 Helm 进行部署的,所以相关的配置如下:
## Configuration for kube-state-metrics subchart |
这样配置完之后,Prometheus 就可以查询到这 2 个额外的 kube_pod_labels,kube_node_labels 指标了。
具体的实现方式这个 Pull Request:https://github.com/kubernetes/kube-state-metrics/pull/1403/files